前言
JDBC->Java数据库连接(Java Database Connectivity,简称JDBC) 是Java语言中用来规范客户端程序如何访问数据库的应用程序接口.是Java和数据库之间无关连接的标准Java API.简单点来说,JDBC是用于在Java语言编程中与数据库连接的API.JDBC是面向关系型数据库的
JDBC工作原理
JDBC为多种关系数据库(MySQL,Sql Server,Oracle…)提供了统一访问形式,他是不同数据库访问API的高级抽象,不同的数据库都能够通过JDBC中定义的接口来进行操作,但是真正具体的访问操作实现的方法是不同的,他是由各自数据库厂商提供的.通常把厂商提供的特定于数据库的访问API称为数据库JDBC驱动程序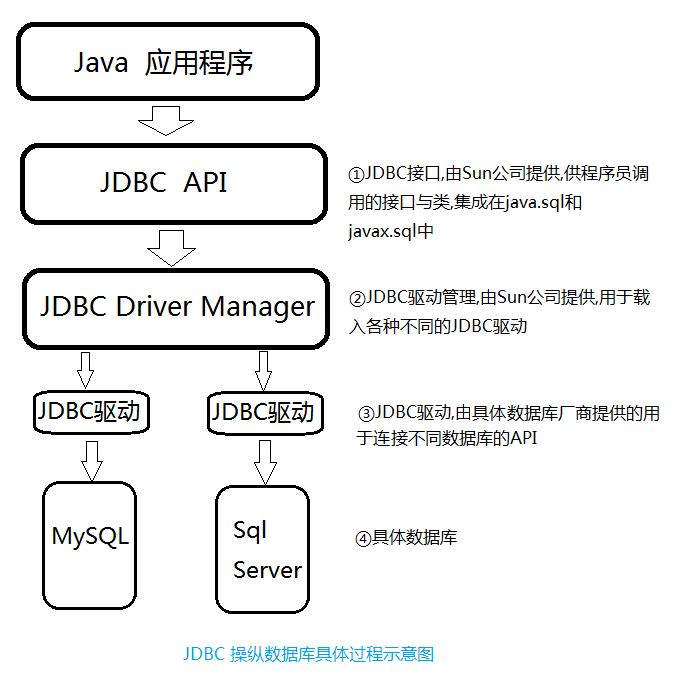
JDBC优势
● Java语言访问数据库操作完全面向接口编程
● 开发数据库应用不用限定在特定数据库厂商的API
● 程序的可移植性大大增强
JDBC的具体使用
JDBC使用流程图
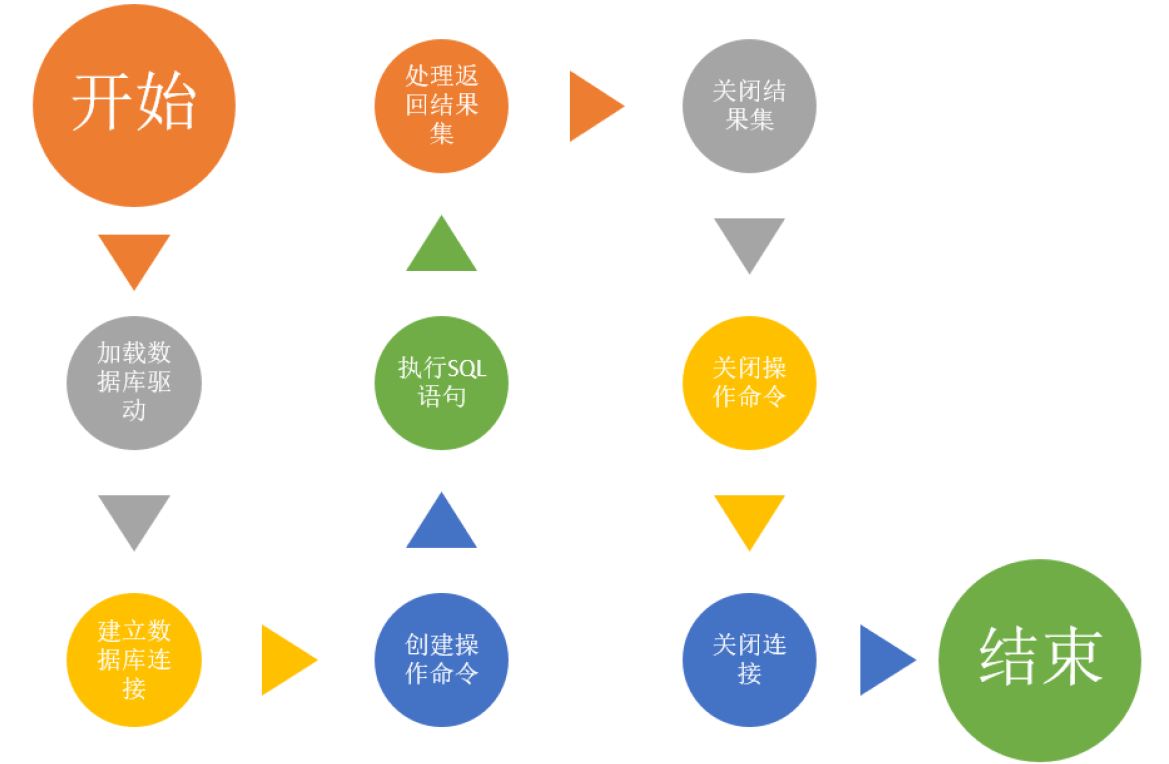
JDBC具体使用步骤分析
这里使用JDBC以MySQL数据库为例对之前已有的scott数据库执行操作
1.加载数据库驱动
首先看一下一般数据库驱动的加载方式;1
Class.forName("数据库驱动类名");
数据库驱动加载原理
一般情况下,在应用程序中进行数据库的连接,调用JDBC接口,都首先需要将特定厂商的JDBC驱动实现加载到系统内存中,然后供系统使用(就像吃饭要有碗,我们先要将工具加载准备好).
想要加载一个数据库的驱动,就要用到Class.forName方法,可能会有人迷惑,Class.forName方法不是加载Java类到JVM中的方法吗,为什么数据库引擎的加载采用的是Java类的加载方式呢?
原因在此,所谓驱动的加载,其实就是实现了java.sql.Driver接口的类.如mysql的驱动类是com.mysql.jdbc.Driver(此类可以在oracle提供的JDBC jar包中找到),他实现了java.sql.Driver接口.驱动的本质还是一个类(class),将驱动加载到内存和加载普通的类原理是一样的.
但是数据库驱动的加载有一个地方我们需要注意:完成加载工作的代码部分实际上是加载的具体的数据库驱动类的静态初始化块
这一点可能会有点绕,我们先看一下MySQL数据库驱动加载类的源码,如下图: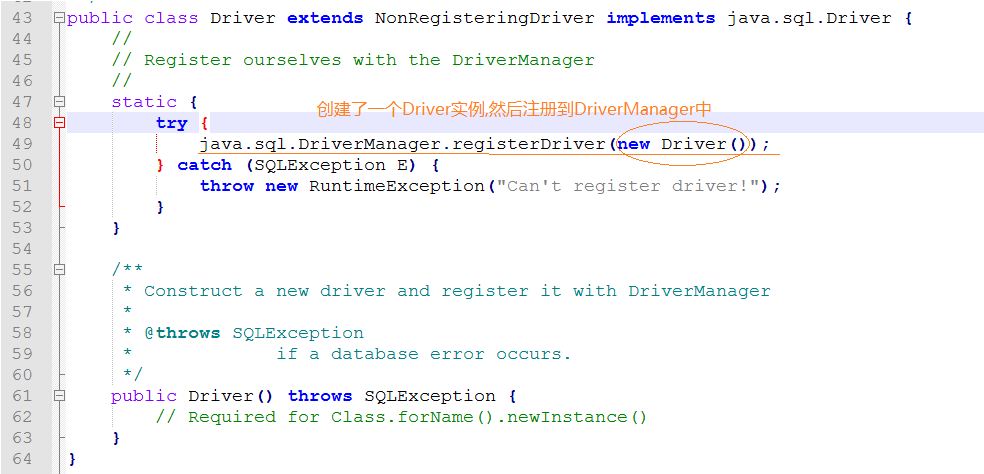
JVM的加载逻辑是:在类被需要或者首次调用的时候就会把类加载到JVM.
所以当我们连接数据库调用了Class.forName语句之后,数据库驱动类就被加载到JVM。此时静态代码块,也就是此处的静态初始化代码块就会被执行,代码段中会创建一个驱动Driver的实例,然后放入到DriverManager中供DriverManager使用。由于是在静态初始化块中完成的驱动加载,所以也就不必担心驱动被多次加载的问题
常用数据库加载到内存的代码
1 | //加载Oracle数据库驱动 |
自动加载
在JDBC 5.1之后实际上我们不需要再调用Class.forName来加载驱动程序了,我们只需要把驱动的jar包放到工程的类加载路径里,那么驱动就会被自动加载
2.建立数据库连接
数据库驱动加载到内存之后就要使用他办事情了。
上面说过,在驱动加载后会创建一个对应数据库的驱动的实例对象,并将这个实例对象交给DriverManager使用。那DriverManager是什么?有什么作用呢?
DriverManager是一个实现了Connection接口的专门用来管理数据库驱动的类。一个程序中如果同时用到了多个不同的数据库,那么就有可能需要同时加载多个不同的数据库驱动,加载入的这些驱动都会交给DriverManager统一管理。那么在使用的时候我们如何进行驱动的区分,使用我们需要的数据库驱动呢?
在DriverManager中提供了一个getConnection(url)方法,此方法可以根据给定的url自动匹配对应的驱动Driver实例并进行数据库的连接,后返回Connect对象,从而进行相对应的数据库交互
● 注意:
1.数据库的访问是基于连接的,即进行任何数据库操作前必须先建立连接,连接上之后可以进行多次操作,在最后一次操作完成后要关闭所有连接,这才算一次完整的数据库操作
2.不同数据库的url格式的写法是不一样的,在JDBC规范里面有定义。MySQL数据库的url写法如下:1
2//jdbc:database://host:port/databaseName?p1=v1&p2=v2
//jdbc:所使用的数据库://主机:端口号/数据库名?user=用户名&password=密码
以我本次使用的数据库为例建立连接:1
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/scott?user=root&password=zhang");
这样便建立好了我指定的数据库和Java程序的连接,接下来就可以使用Java来操作这个数据库
3.创建操作命令
当我们加载好了需要使用的数据库驱动,并且正确的建立了与该数据库的连接.那么准备工作已经完成了90%,我们还需要最后一位朋友 —>
Statement接口,他能够帮助我们用Java语言很好的和数据库进行交流沟通,他可以将我们之后在Java中创建的sql语句搬运到数据库中执行然后将结果再返回回来,相当于一个搬运工.简单点说,使用Connection连接到数据库,由Statement创建和执行SQL语句
当建成一个Statement对象之后,他提供一个工作空间供用户创建不同类型的SQL语句并执行,由于Statement只是一个接口,所以不能直接使用它创建对象,JDBC中规定我们使用Connection接口中的createStatement方法来创建Statement接口的对象,具体方法如下:1
Statement statement = connection.createStatement();
这样我们便创建好了一个可向数据库发送SQL命令并返回结果的传送对象,接下来我们要做的就是创建SQL语句,进行相应的数据库操作并且返回相应的结果了~
4.执行SQL语句(以查询语句为例)
首先,我们需要先写入自己需要执行的SQL。我们知道SQL语句有很多类型,所以对于不同类型的SQL我们需要使用的方法也是不同的,但是这些方法都有一个共同点,即他们都是Statement对象所具有的方法
在这里展示部分方法1
2
3//Statement对象的executeQuery()方法,执行SELECT查询语句.
//Statement对象的executeUpdate()方法,执行INSERT,UPDATE,DELETE等语句
//Statement对象的execute()方法,执行CREATE,DROP查询语句.
这些方法怎么用的呢,此处以查询语句来做范例举个例子(因为查询语句比较特殊,他会返回一个查询的结果集,并且我们需要正确的接收这个结果集):1
statement.executeQuery("select ename,empno from emp");
可以看到,查询语句使用executeQuery()方法,并且数据库查询语句是以字符串形式进行参数传递的
在数据库中,我们执行了一条查询语句,就会有相应的输出结果(表格),JDBC中也不意外,当查询命令通过Statement对象在数据库中执行之后,会将结果作为一个结果集返回到Java程序当中,此时我们需要一个容器来盛放这个结果集,JDBC中提供了ResultSet接口,他就像一个容器,以二维结果集的方式帮我们保存查询的结果1
2//执行查询语句并返回结果集
ResultSet resultSet = statement.excuteQuery("select ename,empno from emp");
5.处理返回结果集
当执行了一个查询语句,查询的结果会保存在结果集中(其他类型语句没有返回的结果集),现在我们的任务就是来读取这个结果集(即能够直观的看到查询结果)
处理本例结果集代码示例:1
2
3
4
5
6
7
8
9
10ResultSet resultSet = statement.executeQuery("select empno,ename from emp");
while (resultSet.next()) {//如果返回true表示有下一行记录,则否无记录
int empno = resultSet.getInt("empno");
String ename = resultSet.getString("ename");
System.out.println(
String.format(
"编号:%d, 姓名:%s",empno,ename
)
);
}
在第四步中我们说到查询语句结束后会返回一个二维的结果集,这个结果集内部维护了一个读取数据的游标,默认情况下,游标在第一行数据之前,当调用next()方法时候,游标会向下移动,并判断此时结果集中是否包含数据,如果包含数据就返回true.结果集还提供了很好的getXXX方法用于获取结果集游标指向当前行数据
这样便处理好了一个查询SQL的结果集(如果是非查询语句就不会返回结果集了,也自然不必做如上的处理操作)
6.关闭结果集
为了确保 JDBC 资源不在出现异常或错误等情况下被不正常关闭,我们应该在使用完 JDBC 资源之后关闭且释放它们.不正常关闭 JDBC 连接会导致等待回收无效的 JDBC 连接。只有正常的关闭和释放 JDBC 连接,JDBC 资源才可以被快速的重用使性能得到改善。
首先我们先回顾一下我们都打开了哪些连接:
在加载完数据库驱动之后我们首先连接了我们需要使用数据库(Connection),连接成功之后,我们创建了操作命令(Statement),用它来贯通Java程序和数据库之间的具体命令交互,然后由于是查询语句我们需要得到他的查询结果,所以又使用了结果集(ResultSet)
以上三个主要的资源都是需要进行关闭操作的
而首当其冲的就是结果集,我们需要先关闭结果集1
2//关闭结果集
resultSet.close;
7.关闭操作命令
1 | statement.close(); |
8.关闭连接
1 | connection.close(); |
关闭并释放资源扩充
1)Connection,Statement,ResultSet三个接口都继承了AutoCloseable接口,因此都可以实现自动关闭(在try里直接创建对象,实现自动关闭)
2)关闭的顺序和连接的顺序应该相反:先关闭结果集ResultSet,在关闭操作命令,最后关闭连接,不能反着进行.因为先关闭Connection会导致其拥有的Statement和ResultSet也随之关闭.如果在对Statement和ResultSet进行引用就会抛出异常
3)连接后及时处理:Connection是很珍贵的资源,在连接好数据库之后应当尽快进行相应的操作.这就意味着连接得到Connection后就应该立即构造Statement查询并得到ResultSet,并且得到结果集后应该立即读取并解析!这三个步骤千万不要多线程进行,或者分解在若干个方法中各自进行,因为一旦connection先释放就会导致其余两者无法使用,这就会导致一些不可预计的后果;
执行查找sql语句(R)和其他sql语句(CUD)在方法上的不同选择
在执行查找语句的时候: Statement类提供给我们的方法是executeQuery(),这个方法是专门用来执行sql查找语句的,他会返回一个结果集 ResultSet,这个结果集中包含着所查找到的所有内容.我们可以使用一行一行的读取的方式来处理这个结果集;
而在执行其他sql语句,例如删除,插入,更新等改变表内容的sql语句时,Statement类提供给我们的方法是executeUpdate().十分形象,就是用来更新表数据的,此方法会返回一个int类型的整数,这个整数代表着更新成功的sql语句条数
在平时使用jdbc时应该注意方法的选择问题
PrepareStatement与Statement的不同与优点
防止sql注入,安全性大大提升
什么是sql注入攻击
先看一个例子:
Sql代码:1
String sql = "select * from tb_name where name= ' "+varname+ " ' and passwd= '"+varpasswd+ "'";
如果我们把[ ‘or ‘1 ‘ = ‘1]作为varpasswd传入进来.用户名随意,看看会成为什么?1
select * from tb_name='随意 ' and passwd = ' ' or '1' = '1';
因为 ‘1 ‘= ‘1 ‘肯定成立,所以可以任何通过验证.
那我们把[ ‘;drop table tb_name;]作为varpasswd传入进来,则:
Sql代码变为:1
select * from tb_name = '随意 ' and passwd = '';drop table tb_name;
这不就直接把一个表删了吗,如果表的内容十分重要那就造成了很大损失.
而如果使用预编译语句.你传入的任何内容就不会和原来的语句发生任何匹配的关系.(前提是数据库本身支持预编译)
只要全使用预编译语句,你就用不着对传入的数据做任何过虑.而如果使用普通的statement,有可能要对drop,;等做费尽心机的判断和过虑.
sql注入标准概念:由于dao中执行的SQL语句是拼接出来的,其中有一部分内容是由用户从客户端传入,所以当用户传入的数据中包含sql关键字时,就有可能通过这些关键字改变sql语句的语义,从而执行一些特殊的操作,这样的攻击方式就叫做sql注入攻击
PrepareStatement怎么防范sql注入
PrepareStatement称为预编译指令,他可以预先加载一个没有参数的sql语句的主体部分,并且sql语句的参数部分可以暂时使用占位符?来代替
这有什么好处呢? –> PrepareStatement实现了sql语句主体和参数的分离!使用statement时如果用户传进来的参数有sql的关键字,那么这个语句是会把参数中的sql关键字当作语句中真正的sql关键字,由此造成了sql注入的隐患,而PrepareStatement实现了参数和sql语句主体的分离.在原本参数的部分暂时使用?来代替,然后用户传入的参数就是?处的值,这样即使传入了一些sql关键字,也只会被当作参数处理,而不会和其他关键字发生关系.从而有效的防御了sql注入攻击
PrepareStatement可以执行多条sql
statement只能使用execute(sql)方法一次执行一条sql语句,而PrepareStatement可以预编译多条sql语句,然后分别执行;所以prepareStatement可以批量处理多条sql,大大提高了效率,这也叫做jdbc存储过程.但相应的prepareStatement的开销就比较大,对于一次的sql操作,还是使用statement比较好
预编译,对于批量处理可以大大提高运行效率
statement每次执行sql语句,相关数据库都要执行sql语句的编译,preparedstatement会先在数据库进行预编译,并且把预编译过后的语句缓存在数据库中,下次在有类似的sql语句则不需要进行编译,只要将参数直接传入编译过的语句执行代码中(相当于一个函数)就可以直接执行.试想,如果有大量sql语句,并且有很多重复,那么由于prepareStatement具有缓存性质,那么效率可是要提高不止一点
附
一个简单的jdbc插入+查询例子
1 | public class Test { |
注意使用jdbc前mysql的jar要准备到位
各种数据库对应的jar包(在各自官网都能够下载)
此处给出MySQL数据库对应jar包地址:https://dev.mysql.com/downloads/file/?id=476198
各种数据库对应的驱动类名和URL格式
